



ad.watch - 深入政治宣传的背后:关于要完成这项调查工作您应该知道的事
【2020年11月20日存档】这篇文章很珍贵。通常情况下我们能看到的只是一个项目的推出,但是很难知道项目在构建过程中所遇到的问题和解决方式;而这些过程将比项目本身对于学习者的帮助更大。在这里,调查人员不仅提供了思考方式、还介绍了很多工具,希望想要构建类似项目的中国调查人员能从这篇记录中获得经验和灵感


两位调查员记录了他们创建 ad.watch 项目的过程,这是一个对 Facebook 上的政治宣传进行公开研究式调查的项目。它从一个有限的努力变成了一个不断增长的资源,促进了对全世界政治宣传的深入了解。
ad.watch 可以发现被安置在 Facebook 和 Instagram 上政治广告/政治宣传的信息。
互联网上的很多广告都是给用户量身定做的,被称为定向宣传。定向广告利用人们的心理、行为等各类信息 —— 目标是精准地操纵您,为每个人呈现针对性的宣传。
这种差异可能体现在内容、设计、传递、或其他特征上。定制的信息可以对目标用户的心理或行为特征分析过程中产生的假设进行测试。
因为如今的政客们都会利用网络平台来宣传他们的竞选活动,推广他们的信息,而这些平台根据用户的个人信息数据分析来传递广告,所以 “个人即政治” 这句话有了一个全新的维度。
然而,要理解这些机制却并不简单。广告投放的基础设施是在黑箱中运作的,各平台都在费尽心思地混淆他们的机制,并建立了许多障碍阻止任何外界理解这些操纵手段是如何运作的。通常情况下,即使是花了钱的广告商自己也无法了解自己的广告会被推到什么样的用户面前的全貌,也不会知道为什么这样布置。
Nayantara 和 Manuel 创建了 ad.watch 以了解宣传如何在线传播。

社交媒体平台上政治广告数据
ad.watch 汇集了39个国家300多个政治人物在 Facebook 和 Instagram 上发布的政治广告。它包括可视化的数据和故事,让您可以浏览这些广告,并对它们进行单独分析,或基于每个国家、政党和其他类别的数据集。
该项目强调,为了了解政治宣传如何在网上发挥作用,我们不能简单地研究它的外观或内容。至关重要的是,还必须关注它是如何传播的。这意味着要研究这些广告如何迎合不同类别的人 —— 根据目标人群的居住地、年龄、性别等进行分类。
在2019年底撰写这个方法论案例时,发布这个项目已经五个多月了。人们对它的反应非常积极,报道选举和社交媒体的记者已经使用它来调查一些国家的问题。
“我很久以来一直是调查记者,而这样的数据对于报告数字时代的竞选活动至关重要。如今仅查看被披露的报告中的捐款和支出已经不够了” —— 在 HackerNews 上共享了 ad.watch 链接的用户写道。
该项目已被 Vice、Huffington Post 和 The Hindu 等新闻媒体和科技网站所报道。英国的 SkyNews 和奥地利的 ORF 等电视媒体利用这些数据来揭秘英国政治和奥地利选举的幕后故事。它还为正在进行的关于政治广告和平台政策的对话提供了素材,并在荷兰、阿根廷、挪威、美国和印度的艺术展览中展出。
但走到这一步并不容易。研究人员问自己的问题随着时间的推移而改变,专业知识和技能并不总是与那些想要完成的任务相匹配。试图了解一家异常强大的公司如此晦涩的基础设施的运作本身就是一项艰巨的任务。
由于一开始并没有一个具体的目标,所以研究人员是按照自己感兴趣的线索,尝试绕过障碍的。因此,本文将通过不同的实践、道德、技术和政治考虑来叙述 ad.watch 的调查之旅。

理解印度大选
2019年4月,印度大选开始时该项目的研究人员就在印度。这应该是历史上最大规模的一次民主实践。
由于印度国土面积大,人口超过13亿,议会席位多 (545个),所以从2019年4月11日至5月19日的一个月时间里,选举要分七个阶段进行。不同地区在不同的日子举行选举。
由于两位研究人员都对技术和政治感兴趣,他们开始观察互联网、数据和社交媒体公司在选举中的作用。对了解新媒体形式如何在选举过程中发挥作用,尤其关注。
电视、报纸和其他传统媒体在政治竞选中的作用相当好理解 —— 这有适用于它的法规,并且已经成为大众文化的主题。但是,对于社交媒体和有针对性的政治广告之间的关系,以及监管者、公众和好奇的研究者将如何处理这一问题,公众几乎没有什么意识和见解。
在选举期间,社交媒体平台发展迅速,在某些情况下,是社交媒体平台主导了媒体生态系统。像 “热门话题”(在特定时间流行的话题)这样的互联网现象也影响着传统媒体的报道和辩论方向。
然而这些现象 —— 关于为什么是这些、而不是那些,成为 “”热门“,以及它们是如何产生和传播的 —— 却相当不透明。这使得立法者或普通公众很难有适当的回应。这种状况是研究人员关注社交媒体上选举宣传的一个动机。
由于印度选举法早在使用有针对性的数字广告之前就已出台,研究人员不得不怀疑这些法律将如何在社交媒体平台上执行,尤其是在选举交错进行的情况下。研究人员特别好奇的一个细节是,在社交媒体上是否会遵守 “静默期”,以及印度选举委员会将如何监督。
【注:静默期是在选举日之前的某段时间内,不允许政党宣传、组织集会或发布广告。这是为了给选民一个时期,让他们可以反思和下定决心,而竞选活动不会产生其他可能左右选民投票决定的影响。】
在印度,宣传工作在各种平台上进行。最常见的如 WhatsApp、Facebook、Instagram、Google 和 Twitter 都被以有趣的方式使用,但其他平台如 ShareChat 和 TikTok,也是大量有组织和无组织宣传的主要媒介。调查人员开始留意这些平台甚至 Swiggy、PayTM 等送餐和金融科技应用所采取的不同的选举相关措施。
调查人员研究了一段时间后发现了不同的方法:到了2019年年中,TikTok 推出了一项功能,通过这项功能,搜索结果和流行的政治标签会带有一个公益广告,要求人们防范 “假新闻”;其他的平台,比如谷歌,在谷歌的广告平台上播放广告之前需要得到地方当局的认证。
在经历了几次关于他们在操纵选举中的作用的丑闻后,Facebook 面临着很大的压力,也不得不采取点行动。

没有一个单一的,明确的指导方针或方法,所有的平台都在分享政治宣传。每家公司都在试水,看看如何应对印度选举和政治内容的泛滥。
为了进一步探索这个问题,必须决定监测哪些数字平台。由于没有时间或资源来调查所有的平台,研究人员决定将调查的初步部分集中在 Facebook 上,因为它是印度使用最广泛的在线广告平台之一。
【注:截至2020年初,每月有超过2.41亿活跃用户,Facebook 在印度的用户数量超过任何其他国家。 Facebook 恰好也是继 WhatsAapp 之后在印度使用最广泛的社交媒体平台之一,WhatsAapp 也由 Facebook 拥有。换句话说,如果您在中国进行这项调查,您应该瞄准微信。】
开始这项调查并不容易。 Facebook 最近推出了旨在使政治广告在印度和其他地方更加透明的工具。
Facebook 的广告库为人们提供了一种通过关键词搜索和页面名称搜索来浏览政治广告的方式。但当研究人员开始探索它时,发现了它的问题:搜索查询并没有返回全面的结果 —— 只是选择了一些调查人员不清楚其逻辑的广告。此外,由于广告没有被贴上任何独特的标识符来追踪,所以无法找到之前在工具中可能已经被注意到的广告的确切副本。
调查的目的是检索数据来监测七阶段选举中的静默期,这意味着需要按地区和广告运行的时期来过滤广告。这样的调查超出了该广告库能够提供的范围。(数月后,广告库为每个广告活动都贴上了独特的数字代码或 “标识符”,以实现可追溯性。)
这迫使调查人员寻找其他方式来监视广告以进行查询。他们得出的结论是,这项研究需要构建自己的广告数据库。
经过进一步的挖掘,调查人员发现了一个不为人知且几乎没有记录的工具,名为 Facebook 广告资源库API,在2019年研究它的时候它刚刚发布。当年所有可寻找该工具信息的地方 —— Github、Reddit 等论坛 —— 都对该API的使用保持沉默。
Facebook 几乎没有做任何解释。调查人员希望找到使用该API的方法有可能以编程的方式建立自己的数据库,并对数据提出更有意义的问题。
获得对此API的访问涉及几个艰巨的步骤:
首先必须有一个 Facebook 帐户
此帐户的名称必须与政府发布的官方文件的名称完全相同
必须在帐户中添加电话号码并启用双因素身份验证
必须从 Facebook 接受的选定文件清单中(例如驾照等)提交身份证明的副本
根据调查人员的国籍,还必须采取其他步骤
此列表因国家/地区而异。
尽管要获得验证账户已经具有挑战性,但获得使用该平台的权限后,学习如何使用该平台同样具有挑战性。
熟悉这个API
调查人员终于接触到了 Facebook 的这个API,但在这个阶段对如何使用它还不太了解。在学习使用它的过程中,调查人员遇到了如何创建查询的诸多问题,并且也遇到了如何将结果重新利用成有用的表单的问题。

Manuel:
我花了很多天的时间来了解如何创建查询以及首先可以查询什么。在没有适当的该API文档的情况下,而且在其他论坛上也没有太多关于它的讨论(也许是因为它是新发布的),这一切都是新的和未知的领域。
为了使用这个平台,我必须设计一个查询,向 Facebook 询问我需要的数据。
一开始,我通过 &search_terms 参数来查询广告,它返回所有包含相关关键词的广告。例如,通过查询 &search_terms=‘modi’,我收到了所有包含 ‘modi’(2019年印度大选候选人)文字的广告,并显示在 &ad_reached_countries=[‘IN’] 参数中指定的国家。这些国家是通过两个字母的 ISO国家代码来指定的,本例中印度为IN。
通过搜索词查询 API,调查人员能够获得包含某个特定词的所有不同广告。然而,这并不适合全面了解印度某党购买的所有政治广告的任务,因为最宽泛的关键词搜索总是会将一些广告排除在范围之外。此外,有时广告的语言并不是英语,或者包含表情符号等无法预料的 unicode字符。
调查人员没有通过关键字的方法进行搜索,而是尝试使用参数 &search_page_ids=,但他们很快了解到,搜索页面和用关键字搜索是不兼容的,无法同时使用。
他们决定放弃关键词方法,而采用使用 Page ID 作为切入点。他们发现,在一个查询中可以添加多达10个不同的页面ID,他们开始考虑是否可以通过手动收集所有政治行为者的 Page ID 并为每10个页面构建一个查询来收集所有政治行为者的宣传。
第一步是确定需要收集哪些政治行为者的广告。在印度的情况下,这是由 Nayantara 完成的,因为她熟悉背景。然后其他人进行了验证。

一旦得到了感兴趣的主要政治候选人和政党的完整名单,就需要在网上搜索他们的 Facebook 页面,以获得他们的页面ID —— 一个唯一标识每个FB页面的数字。这涉及到每个页面的专用流程。
首先需要找到政治行为者在 Facebook 上的页面。在某些情况下,这些页面很容易找到;而在其他情况下,必须辨别它们是粉丝页面还是官方页面。
有些政治人物有多个页面;有些页面因为联盟或品牌重塑而不断更换名称;还有些时候一些政党和候选人并没有页面。这意味着调查必须做很多工作来了解是否找到了正确的页面。
这些页面上的帖子有时是用地区性语言发布的,而仅在印度就有22种官方语言和9种不同的文字。自然,随着项目的发展,这一挑战也越来越复杂。
收集 Facebook 页面后,调查人员开始执行一个简单但重复的任务:
右键单击个人资料图片,然后在新选项卡中将其打开
在此 URL 中,找到页面ID号,然后选择并保存。通过这种方式映射、收集并验证页面ID
一旦获得了页面ID列表,便组成了查询,看起来像这样:
ads_archive?ad_active_status=ALL&ad_reached_countries=[‘IN’]&fields=ad_snapshot_url,ad_creation_time,ad_creative_body,ad_creative_link_caption,ad_creative_link_description,ad_creative_link_title,ad_delivery_start_time,ad_delivery_stop_time,currency,demographic_distribution,funding_entity,impressions,page_id,page_name,region_distribution,spend&limit=99&search_page_ids=121439954563203,218904931482352,351616078284404,1447651982136257,1473429256300357,192136870799912,290805814352519,241701912507991,245976872240667,163382127013868&transport=cors
如您在上面所看到的,其中还包括其他参数:
ad_active_status=ALL 意味着正在寻找所有有效和无效的广告
ad_reached_countries=[‘IN’] 政治广告必须来自印度(IN)
limit=99 表示只想要99个结果。这个参数很重要,后面将解释为什么
想要获得响应的字段是 &fields = 后面的内容:
ad_snapshot_url,ad_creation_time,ad_creative_body,ad_creative_link_caption,ad_creative_link_description,ad_creative_link_title,ad_delivery_start_time,ad_delivery_stop_time,currency,demographic_distribution,funding_entity,impressions,page_id,page_name,region_distribution,spend
Facebook 随后合并了 &platform_publisher 参数,它旨在告诉调查者广告是否出现在 Facebook、Instagram、Messenger 或 Audience Network 上。
【注:Audience Network 允许第三方应用程序使用 Facebook 的定位基础架构在 Facebook 和 Instagram 以外的平台上投放广告】
对于每个广告,调查寻求的响应如下:
ad_snapshot_url 该广告的快照链接(每个广告的唯一标识符)
ad_creation_time 广告制作的时间
ad_creative_body 该广告使用什么主体创作的(内容通常为文字形式,有时还包括表情符号)
ad_creative_link_title 被添加到内容中的链接(通常会导致需要更多数据的调查)
ad_creative_link_caption 链接附带的说明(例如 “了解详情” 或 “点击此处”)
ad_delivery_start_time 预定投放广告的时间
ad_delivery_stop_time 广告原定停止投放的时间
currency 付款所用的货币
demographic_distribution 广告投放到的人群的年龄和性别
funding_entity 支付广告的实体
impressions 广告可能被浏览的次数
page_id 页面ID
page_name 页面名
region_distribution 广告投放的区域
spend 在特定广告上花费的一系列资金
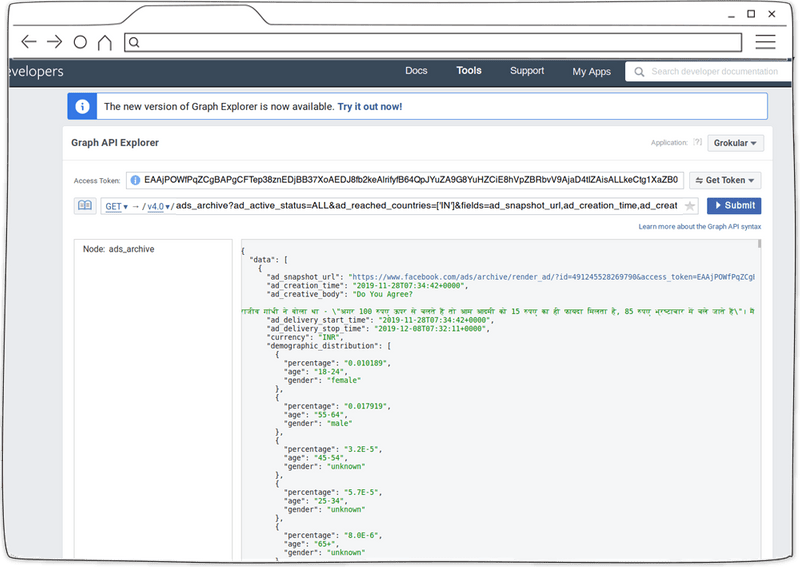
该查询返回了一些数据,这是调查了解数据外观的第一步。
即使到了这个阶段,也只是设法收集到了99个最新广告的数据。Facebook 允许收集多达5000个广告,但是,随着调查人员提高广告请求的数量,查询崩溃的可能性也急剧增加。
这种情况会经常发生,以至于当进行大型查询时,调查人员访问广告资料库API的浏览器选项卡会冻结。所以坚持设置为返回99到200个结果之间。
需要找到一种方法来超越99个结果,这是实际的收集,但也超越了理论上能提供的5000个结果,以便收集所有的广告。
【注:该API查询会因为未知的原因意外崩溃,有时能用,有时不能用,有时对完全相同的查询提供不同的错误结果。
这个时候会明显感觉到,Facebook 对该API缺乏兴趣,这与调查人员系统地收集数据可能存在的障碍相吻合。
障碍的规模之大让人怀疑平台是否 Facebook 有意阻止调查人员访问数据,而广告资料库和API的发布是否只是在用一个故意不合适的工具来粉饰透明度问题。
这也发生在 Facebook 打击很多软件公司从常规API收集数据的时期。这些禁令可以看作是剑桥分析公司丑闻之后的战略举措,Facebook 利用丑闻打着保护用户隐私的旗号限制透明度。
监视资本主义的有效性和 Facebook 广告平台的竞争优势顺理成章地取决于对其内部运作的最低限度披露。】
在查询结果页面的底部,有一个带有“分页”号的网址。这个链接会指向另一个URL,在那里出现下一页的结果。以此类推。如果在下一个查询中包含这个分页,它将引导到第2页,然后是第3页 …… 它看起来是这样的:
&after=c2NyYXBpbmdfY3Vyc29yOk1UVTFPREV3TXpRd01Eb3pNRGM0Tmprd056WTRNamd6T0RVPQZDZD
在查看所有结果之前,无法知道会有多少页的结果。但这样一来,至少可以手动浏览每一页的结果,并将浏览器中的数据复制到文本文件中。
数据是以JSON格式给出的,每一页都包含文件开头和结尾的语法。这意味着如果按照数据的来龙去脉存储数据,就必须为每一页结果创建一个文件。调查人员很快就意识到,将每99个广告的结果保存在一个单独的文件中将是一项极其艰巨和低效的任务。所以他们寻找了一种方法来复制JSON查询的结果,去掉页眉和页脚。
在第一页,保存了页眉和内容,但没有保存页脚;在最后一页保存了内容和页脚。这样就可以在一个JSON文件中获得10个政党和政治人物的数据。为了让这个系统成功,需要在删除的页脚处添加一个逗号 (,) 和一个换行符。
调查人员必须不断地小心不要因 “过度使用” API而被阻止,同时也要避免不可预测的崩溃。这种试错的方法也带来了其他问题,比如被API的速率限制所阻挡。
Facebook 没有指定使用限制,但一些限制显然是存在的。调查人员第一次想用 Python 脚本自动收集数据的努力被阻止了,似乎 Facebook 是故意让数据自动收集变得困难,如果从较小的、较慢的人工交互中进行查询,会有更多的成功机会。
因此,目前的挑战是如何使广告收集自动化,同时又使其看起来像是人工操作的那样好。
调查人员开发了一种非常机械和重复的模式来手动收集数据。工作流程如下所示:
加载一个查询
复制结果(页脚除外)
点击下一页
在下一页加载时,将数据粘贴到文本文件中
添加逗号和换行以保持语法中数据的连续性
切换标签
复制没有页眉和页脚的数据
粘贴到文档中
添加逗号和换行…
Manuel:
像 ctrl+c、ctrl+v 和 alt+tab 这样的快捷键有助于提高这个机械过程的效率。为了使该API的工作和我自己的行为高效同步,我调整了 &limit= 参数,使其返回的数据在浏览器中的加载时间与我完成复制粘贴数据到文本文件这部分工作流程所需的时间相同。
人类行为的随机性规避了大部分时间的 Facebook 阻塞和崩溃。尽管如此,这依旧是一项极其缓慢、重复和细致的工作。每天花上几个小时的时间来进行这种人工收集数据的工作,通过这种方法建立几百万字节,然后是几千兆字节的JSON数据,这真是磨练耐力。
我的效率变得非常高,以至于我可以不假思索地工作,体现出所需的动作,就像骑自行车那样。所面临的挑战是如何让自己保持清醒,同时继续完成任务。通过这个系统,我们最终收集到了我们在印度研究的政治行为者的所有广告数据。

违反静默期
印度选举法规定了选举日之前48小时的静默期 —— 这意味着在选举时间之前的两天内,所有的竞选活动,包括线上和线下的广告都被禁止。如果在互联网上遵循这些规则,调查人员对 Facebook 广告资料库API的查询就不应该返回从2019年4月10日到2019年4月11日(第一阶段选举日)的广告。
为了查看是否是这种情况,您需要找到一种方法来理解收集到的数据。它是JSON格式的,所以需要能够处理和帮助分析JSON数据的软件。
Manuel:
在查找网络论坛的时候,我了解到了 Tableau,这是一款数据可视化分析软件。我下载了 Tableau Public 的试用版,这是一款适用于运行 Windows 操作系统的计算机的软件。
使用 Tableau Public 从一开始就不是很简单。我需要从互联网上的各种论坛和 YouTube 上的解释中得到一些提示,才能明白掌握JSON格式的数据后要做什么。
但是 Tableau 并不能在 Linux 上使用,而我的电脑上通常运行的是 Linux 操作系统。所以为了能够使用 Tableau,我下载了一个叫做 VirtualBox 的虚拟化软件。该虚拟化软件可以让你运行一个与电脑上安装的操作系统不同的操作系统,而不需要在设备上再添加一个操作系统。

设置和安装好后,就可以用 Tableau 来理解数据了。调查人员必须玩转 Tableau,以了解如何使该软件读取调查所拥有的数据,如何使它读取多个数据文件,这种组合数据的结构必须是什么,以及 Tableau 一般提供什么功能。
调查人员能够提出以下问题:
在特定时间段内展示了哪些广告?
哪个政党在哪个地区展示广告?
印度南部的老人正在看到什么广告?
调查人员意识到对了解哪些广告违反静默期有帮助的一个参数是 “ad_creation_time”,它记录的日期是这样的格式:“2019–04–02T17:22:45+0000.”
但经过进一步的研究,调查人员意识到,广告创建的日期和时间并不一定与广告交付给人们的时间一致。
为了了解广告运行的时间,比较有用的参数是 “ad_delivery_start_time” 和 “ad_delivery_stop_time”。由于印度选举的多阶段性质(即 投票发生在不同的时间在不同的地区),调查还必须让静默期时段与要进行民调的相应地区相匹配。所以使用了 “region_distribution” 这个参数。
调查人员对数据进行了过滤,以显示在特定区域的静默期内活跃的广告,并对其进行了进一步分析。结果开始发现,这些违规行为并非偶然或特殊,而是常规性的。
利用 “ad_start_date” 和 “ad_stop_date” 这两个参数,调查人员识别出了在静默期运行的广告。除此之外,还使用 “region_distribution” 来分离特定状态下在静默期运行的广告。

就这样,调查人员开始系统地收集所有违反静默期的广告。此时调查已经即将进入选举的第五阶段,所以收集了前四个阶段的违规情况。调查人员了解到,其中一个最重要的指标 —— 花在广告上的金额,只提供了一个范围。
这使得确定政治行为者支出的工作变得复杂。但由于这是一个如此重要的信息,调查人员决定达成一个折衷方案,计算出每个广告的平均范围。
正如所料,这些信息导致了几个有趣的发现。一些制作了数千条广告的政治行为者,反而比制作广告数量较少但花费较大的政治行为者花的钱要少。
调查人员了解到,广告的数量并不总是与花费的金额成正比。对于静默期的调查来说,这意味着即使一方的违规广告多了很多,也有可能另一方在打破静默期的定时广告上花费了更多的钱。这些都是重要观察。
在前四个阶段中,调查人员总共收集到了2235个广告,都违反了印度的静默期。
一旦意识到有具体的违法证据,就会面临许多研究人员和调查人员都在苦苦挣扎的问题:“我们能对此做些什么?”
此时,该国仍处于多阶段选举中,还有几周就结束了。调查人员的选择是,要么通知 Facebook 违规行为,要么通知印度选举委员会(EC)。当然还有第三种选择:继续记录下来,并写出来。然而,在没有媒体关系或出版平台的情况下,调查人员不确定这是否是最有影响力的途径。
尽管并没有真正期待选举委员会(EC)有能力解决甚至是否倾向于解决这个问题,但调查人员更犹豫是否要将这些证据通知 Facebook。
向 Facebook 报告这些违规行为意味着,调查人员将确保民主进程完整性的责任交给了一家有着糟糕问责记录的外国私营公司,而不是一个民主机构。
这将意味着将主动委托 Facebook 承担对选举进程有重大影响的监督职能。虽然可以想象向 Facebook 报告会是让广告被撤下的一个更快捷的方法,但是。作为一个原则问题,调查人员决定先向选委会报告,并向公众公布调查结果。
调查人员提交了一份报告,其中包含有关2235个违规广告的数据的证据,并按选举的四个阶段进行了分类,并给出了简短的解释。
不出所料,没有收到任何回应。
除了向EC提交报告外,调查人员还决定撰写有关报告。 HuffingtonPost India 同意将这份调查与 Facebook 政治广告违反静默期的调查结果结合起来。

在选举的其余阶段,侵权行为仍在发生,迄今为止尚未采取任何行动。
通往 ad.watch
在寻找关于静默期具体问题的答案的过程中,调查人员发现了其他有趣的通过 Tableau 阅读数据的方法。这里的主要挑战之一是了解如何组织数据。由于调查收集的数据是在多个文件中,必须确保文件以正确的方式组织起来。
调查人员在设计数据收集的时候,根据文件的大小进行了限制。这意味着,如果一个政治行为者的广告数据量非常庞大(比如特朗普的广告数据就非常庞大),那么文件中包含的广告数据将少于10个政治行为者的标准数量,而只包含一个政客的数据。
通过大量的试错,以及在 Tableau 社区论坛和 YouTube 上关于该工具的视频的帮助下,掌握了数据的结构。既然它是一个如此流行的数据分析和可视化工具,那么要找到这些细节的答案,就需要探索已有的论坛。
除了沉默期的违规行为,调查还发现了其他有趣的细节:政治广告的信息架构、可用的信息类别、以及缺失的数据,都很有启示意义。
例如,尽管允许用户在广泛的选项中进行身份识别,但 Facebook 还是将人们的性别划分为男性和女性的二元组。这是一个有趣的窥探,让人们了解到用户体验层面的工作方式与为营销而设计的后端基础设施的工作方式有多么不同。


当调查人员成功揭开静默期违规事件后,印度大选已经顺利进行,2019年欧洲议会选举也即将到来。借此机会,调查人员也开始挖掘西班牙各党派的数据,为欧洲议会选举和2019年的西班牙市政和全国选举做准备。慢慢地,调查开始扩大数据收集和研究的范围。
虽然现在正在收集和探索不同背景下的 Facebook 广告数据,但调查人员对写一些自己没有背景知识的国家的故事感到不合适。除此之外还觉得这样做在某种程度上是不正确的,即使对这些地方有一部分了解,或者找到了来自不同国家的合作者。
简单说,建议公民的调查人员着眼于本地,您将获得比外界更便捷的洞见。
但在坚持自己的路线的同时,调查人员也想让其他国家的这些数据能够被获取。于是决定,将收集所有国家的现有数据,但是,将分析和调查工作留给可能有兴趣的人去做。
调查人员与世界其他地区正在进行选举观察的同事和朋友联系,看看收集到的数据是否会直接对他们有用,或者他们是否有兴趣倡导在这些地区也发布类似的数据。
比如在菲律宾,Facebook 是杜特尔特政府进行虚假宣传活动的重要渠道。菲律宾也恰好是剥削和创伤性的内容编辑合同工劳动力市场之一。调查人员采访了菲律宾的朋友和同事,分享了这项调查的内容,并听取了那里的发展和准备情况。
一旦决定开始在全球范围内研究政治广告,就必须认真考虑采取什么方法,哪些团体或个人已经在从事与政治广告相关的项目,以及可以填补哪些空白。
比如 FBTrex 是一个帮助用户通过安装浏览器扩展来收集包括政治广告在内的帖子元数据的工具,这些帖子会在他们的新闻源中显示出来。
【提示:Facebook Tracking Exposed(FBTrex)是一个项目,其愿景是个人应该控制针对自己的算法。其中,该项目提供了一个浏览器插件,可以收集您的时间线上所有公共帖子的元数据,并允许您将这些数据贡献给公共数据集,或者将其私藏起来供自己使用。
FBTrex 还允许研究人员(和用户)通过他们的API使用/再利用一部分数据。
ProPublica 创建了一个名为 “政治广告收集器” 的工具,您可以安装一个浏览器插件,收集您在浏览时看到的所有政治广告,并将它们发送到一个数据库中,使 ProPublica 能够更好地分析政治广告定位的性质。
另一个项目 Who Targets Me 让您可以安装一个浏览器插件,收集您的时间线上所有赞助的帖子。该插件将这些数据发送到一个众包的全球政治广告数据库上,它将赞助的帖子与政治广告商的分类列表进行匹配,并得出谁在网上针对您进行宣传的结论。】
调查人员已经熟悉了 Facebook 广告资料库API所提供的信息字段,但并不知道广告商可用于定位用户的信息字段。
这意味着,即使知道某条广告在德里达到了1,000到10,000人之间,也不知道这些是否是广告主为定位广告而选择的参数。调查人员有兴趣知道有哪些选项可以用来管理目标用户。
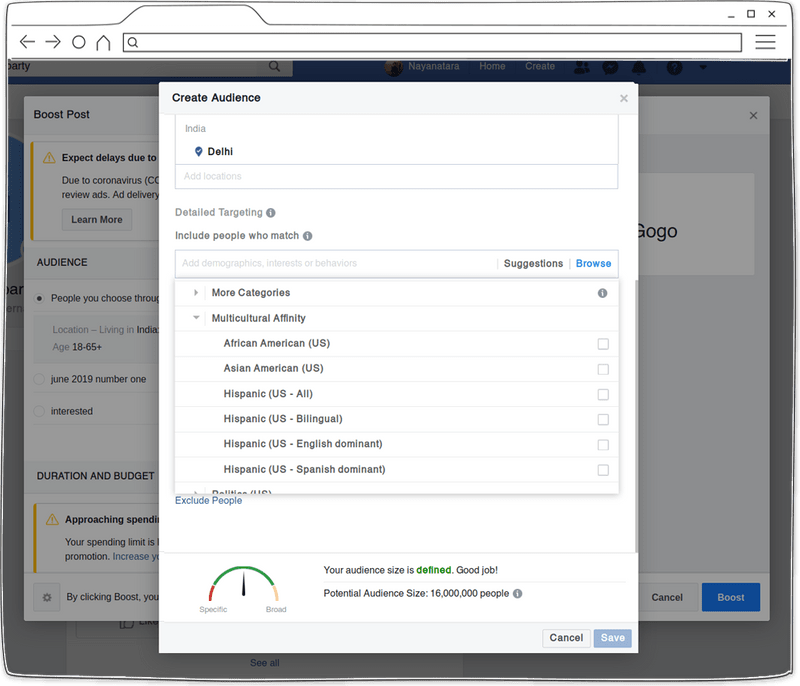
所以调查人员创建了一个虚构的政党页面,并测试购买和定位广告。两个人各创建了一个页面,并对帖子进行了 “提升”。不出所料,从这个窗口可以获得的细节水平远远大于以透明度的名义透露的信息。
调查人员可以通过指定想要针对的 “人口规模、兴趣和行为” 来创建 “自定义受众范围”。还可以输入可能已经表示对这个虚构的业务或活动感兴趣的人的数据,而 Facebook 会提供给 “看似相似的受众” 提供广告。
这些都是标准的宣传方法,但很快即将发现,可用于定位的字段似乎相当有问题,可能会导致各种歧视。例如,调查人员发现一个名为 “庆祝斋月的人的朋友” 的类别。
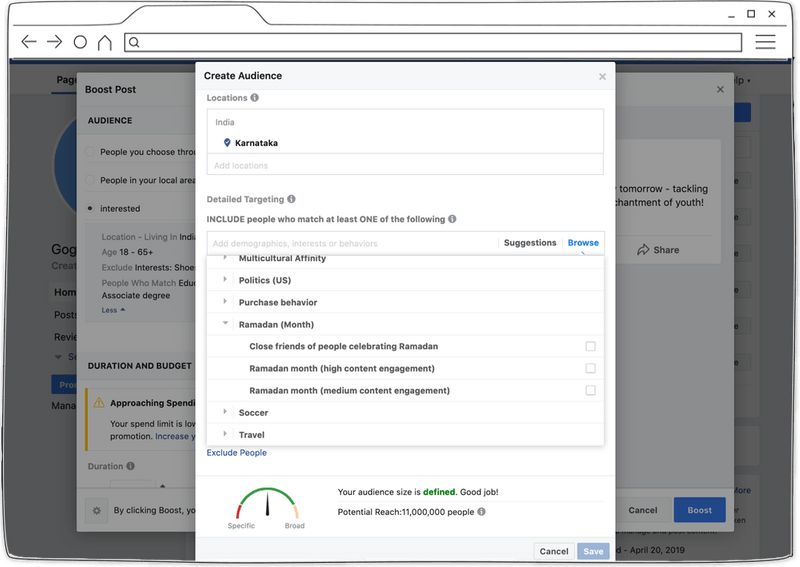
调查人员了解到美国的事态发展,在那里,歧视做法被记录在案,Facebook 也被追究责任。还了解到,Facebook 已承诺在就业、住房和信贷广告方面不允许以种族和性别为目标。
这些类别证实,这类问题在世界其他地方都没有得到解决。例如,上述 “庆祝斋月的人的朋友” 这个选项是一个很容易被用来针对穆斯林的类别,而此时印度的反穆斯林情绪既来自国家,也来自整个社会。
发布 ad.watch
调查人员决定收集世界各地政治人物的数据。
如前所述,调查人员一直在使用 Tableau 进行内部实验,了解数据。此时,他们发现 Tableau 允许在线发布,事实上,它提供了相对动态和复杂的可视化水平。
虽然调查人员跃跃欲试地使用 Tableau 软件来帮助理解数据,但一旦出现发布的问题,就不得不考虑是否要让整个项目依赖于一个专有的、主要由营销部门用来进行数据分析的工具。
还必须考虑到,是否会因为依赖专有软件而使调查的工具变得脆弱,因为该软件可以随时决定撤销访问权。
调查人员探索了其他深受欢迎的开源替代方案,如 Rawgraphs 和 Datawrapper。然而,考虑到数据的大小和特殊性,这些都被排除了。这些替代品中的一些无法分析广告的内容,因为广告有时包含非拉丁语脚本的字符。所以最终决定继续使用 Tableau Public。
【注:令人费解的是,为什么这些备受赞誉的开源免费可视化软件中,很多都无法打开JSON文件哪怕是小片段。
调查人员使用了一个名为 JSONLint 的网站,它可以帮助 “验证” JSON数据 —— 也就是说,帮助发现文件中是否存在格式错误。因为文本字段经常包含不是拉丁字母的东西,还有表情符号和最近版本的 Unicode 中包含的字符。】
于是他们开始用 Tableau 设计自己的可视化界面来浏览数据库。在使用 Tableau 时遇到的一个问题是,它处理这种规模的数据库需要大量的计算资源,超过了5千兆字节。通过虚拟机运行的计算机速度非常慢,或者有时根本无法加载数据。而在有限的财力下购买一台更强大的计算机是不可能的。
Manuel:
我所任教的大学为教师提供了使用英特尔 Xeon处理器和20GB内存的远程桌面。事实证明,这是一个很好的解决方案。如果没有这一点,我们就不得不租用虚拟专用服务器来实现同样的目的。可以通过远程桌面协议(RDP)访问远程桌面。这是一个允许您访问和控制与您不在同一物理位置的系统的协议。
【注:Tableau 仅允许您导入最大128MB的 JSON 文件,因此调查人员必须将文件拆分到该限制以下。他们使用了一个简单的 Python 脚本 json-splitter 来完成该任务。】
想要在希望通过该项目实现的目标之间找到适当的平衡是一项挑战。
作为一个揭露尚未被广泛理解的技术机制的项目,重要的是以一种任何人都可以学习和理解政治广告如何运作的方式来展示它。它需要足够强大,让记者和研究人员可以进行调查。它还需要将 Facebook 广告的基础设施如何运作问题化。融合所有这些元素需要一些时间,调查人员探索了不同的模式。
在使其成为移动友好型或基于桌面的工具之间,调查人员选择了桌面,因为这样可以提供更深入的体验。
当 ad.watch 界面即将完成时,如何更新数据库的问题变得迫在眉睫。如果直接把数据转发给需要的人,也许更新的内容就不那么重要了,但是作为一个活跃资源,调查人员觉得随时更新更为重要。
下一个挑战是让脚本了解某个查询何时结束,以便脚本可以跳转到下一个查询。或者说,如何让文件保持在 Tableau 的限制之下每个不超过128MB。
如前所述,Facebook 对自动查询进行了限制,所以自动化设计开始模仿人类的行为,在查询之间加入随机的时间延迟。从最初的版本开始,这个脚本就成了一个珍贵的数据收集系统,每天都在改进它。通过它,调查人员可以更好地了解了 Facebook API 的工作原理,并尝试收集政党以外的数据。
后来调查人员创建了一个带有 Page ID 的文本文件系统,以及一个单独的带有两个字母ISO国家代码的文件,因此它可以一次性收集多个国家。这个新系统还能够更容易地更新政党名单。

2019年7月26日,ad.watch 的第一次发布是在人工收集数据的情况下完成的,但当时也已经将脚本完善到了可以定期更新数据的程度,事实证明,这对项目的效果极为宝贵。调查人员上线了网站,并在个人社交媒体网络上发布消息进行传播。收到了很多积极的反应,包括记者们利用这些数据来了解 Facebook 政治广告中的问题,注意到各国选举的趋势。
一些经验
1、通过 Facebook 验证
回到调查人员最初尝试访问数据并需要进行身份验证的过程,他们意识到两位研究人员必须面对完全不同的验证过程才能访问 Facebook 的广告平台。
Nayantara:
作为一个 “主要国家所在地” 是印度的人,我不得不接受额外的步骤来核实地址。这涉及到在收到通过邮寄送到我家的代码或 “某人” 到我家的访问之间作出选择。两种选择之间的时间差异很大:邮寄需要三周时间,而拜访我家则在一周内发生。
因为我们想尽快办理手续,也被上门拜访的过程所打动,所以我们决定选择这个方案。

我们在身份识别过程中所学到的东西令人震惊。
提出验证请求后的第二天,我(Nayantara)接到了一名男子的电话,该男子正准备进行此程序。他说,他正在致电 Facebook 进行验证,并询问第二天是否是访问的好时机。

整个过程很有意思,原因有很多,包括展示了印度身份识别技术和相关企业的兴起与 Facebook 等大型科技公司在印度寻找耳目的相互作用,这是 *身份验证即服务* 的一个完美例子。
那次,我问来电者是谁,是哪个公司的。他犹豫了一下,似乎没有想到会有这样的问题。当我们确定我们都会说卡纳达语(印度西南部卡纳塔克邦人主要使用的一种语言)后,我们就建立了比较熟悉和信任的谈话语气。
他说他在一家叫 OnGrid 的公司工作,他的名字叫 Umesh(改名)。Umesh 向我保证,他来的时候我不需要在家,只要有人在那里能确认我住在那里就可以了。
两天后,Umesh 来到我的住处进行核实。他从外面给我的房子拍了照片,在房子附近的一个地标上拍了照片,并得到了和我一起住的家人的签名(因为访问期间我不在家)。

自然,我们对这家 Facebook 的验证服务提供商公司很好奇。OnGrid 是一家印度公司,声称要让印度人 “即时建立信任”,换句话说,就是从事身份信息的交易。他们提供从 “学历验证” 到法院记录查询等各种服务。
两年前,他们曾因一张让人毛骨悚然的图片而成为新闻焦点:利用印度臭名昭著的国家生物识别架构 Aadhaar 进行非自愿的图像识别的广告。作为一个独立的实体,OnGrid 的服务条款和数据政策与 Facebook 关于保留为识别目的提交的信息的政策不同。

Facebook 的政策没有提到外包核查过程的某些内容,也没有提到数据政策在这种情况下如何改变。这可能意味着,Facebook 做出的关于删除与 Facebook 共享的身份数据的承诺,并不是 OnGrid 在满足所谓的 “最后一公里验证” 需求的同时,有义务尊重的。
事实上,Facebook 宣称将永久删除从经历验证过程的用户那里收集的数据。而 Facebook 在印度雇佣的验证公司 OnGrid 则保留了这些数据,用于为其他实体提供 “身份验证服务”。OnGrid 使用人们的数据来创建他们的数据库,以便重复使用并作为服务提供给其他实体。
经过这个过程,我终于完成了我的地址验证,并且可以访问广告资料库API了。
Manuel:
作为居住在荷兰的西班牙公民,我的身份核实过程要简单得多,涉及的步骤也少。然而,一旦提交,最后的受理需要两天时间才能通过,而 Nayantara 在这一步骤中得到的是即时答复。
这些事件有助于了解不同国家不同的数据处理流程,第三方核查行为者参与所造成的脆弱性,以及令人愤慨的事实,即 任何这一切对于获取公共利益信息来说都无法绕过,而这些信息对于了解社交媒体如何干预民主进程相当关键。
2、是否包含图片和视频?
调查人员有一个将广告数据可视化的计划,但视觉内容本身却无法显示。这些数据并不是以独立于依赖API的可下载方式提供的,因此将其可视化是一个挑战。
但即使要找到一种方法来嵌入链接并呈现可视化,也存在另一个问题:带有视觉效果的URL包含 “访问令牌”,这是一个独特的、有时间限制的令牌,链接会在一小时后失效。如果没有浏览者自己的访问令牌,链接就没有什么用处。
【注:广告快照的URL如下所示:
https://www.facebook.com/ads/archive/render_ad/?id=251563729117836&access_token=EAAjPOWfPqZCgBAAJ0csteVNkFJcyxbQZA7m1xbJ8w3fzFRlm6apQ5cAnzsjBNOOJt4zSEE8IxB4k9HcKydhbcd7P4SnNTBn82G7s>gyy5YXX8fmZC0hUGcpQMfZCp3uWaSWeX4urEcNPwB8SM01clzJSqRXPjjh8ZBguzXZC9sc9whaz0hE9MGEj889ztZBW2XNxVfitweUSkVrcKGiwePQQZB7uGBOa
访问令牌是在 access_token = 之后的东西,它是字母和数字的长字符串:
EAAjPOWfPqZCgBAAJ0csteVNkFJcyxbQZA7m1xbJ8w3fzFRlm6apQ5cAnzsjBNOOJt4zSEE8IxB4k9HcKydhbcd7P4SnNTBn82G7sgyy5YXX8fmZC0hUGcpQMfZCp3uWaSWeX4urEcNPwB8S>M01clzJSqRXPjjh8ZBguzXZC9sc9whaz0hE9MGEj889ztZBW2XNxVfitweUSkVrcKGiwePQQZB7uGBOa】
调查人员考虑过使用浏览器的一个插件,如 “下载所有图片” 来刮取广告库的图片。也有许多 Python 中的脚本可以做到这点。然而,Facebook 阻止所有这些刮取技术收集视觉效果。此外,Facebook 还禁止用户在一般情况下进行这种刮取。

一方面,加入视觉效果是很重要的,因为它们对浏览界面的人有回忆价值。但另一方面,调查人员想知道,不用视觉效果来分散人们的注意力可能是一件好事,因为要传达的最关键的方面是,视觉效果本身可能没有它们的元数据的价值更高,比如目标定位。
尽管如此,调查人员也尝试使用 “wget” 命令来执行此操作,但是它不起作用。
最终找到了一种解决方法,使用 Tableau 中提供的功能使 ad.watch 的用户能够输入自己的访问令牌并查看广告的内容。
但是,发布后不久调查人员就发现了一个称为 “访问令牌调试器” 的东西,可以在其中延长每个访问令牌的寿命或有效性。

3、与记者合作
在与记者一起调查数据中出现的故事时,许多人希望看到原始数据。然而,分享数据的时候,却遇到了一个问题。数据中包含了 “ad_snapshot_url” 这个参数,其中包含了前面所说的个人访问令牌。
这个访问令牌对于不同的开发者账户来说是独一无二的,并且会被记录在查询返回的数据中。由于调查人员小心翼翼地不做任何可能让自己对API的访问权被撤销的事,所以必须在共享数据之前将其删除。
但是从每个广告的数据中移除访问令牌必须是自动化的,因为有数百万的广告。在 StackOverflow 中搜索,解决方案相当容易找到,调查人员能够使用 Linux 终端中已经包含的一个名为 “SED”(Stream Editor)的工具。
sed -i -e 's/EAAjPOWfPqZCgBAAJ0csteVNkFJcyxbQZA7m1xbJ8w3fzFRlm6apQ5cAnzsj BNOOJt4zSEE8IxB4k9HcKydhbcd7P4SnNTBn82G7sgyy5YXX8fmZC0hUGcpQMfZCp3uWaSWeX 4urEcNPwB8SM01clzJSqRXPjjh8ZBguzXZC9sc9whaz0hE9MGEj889ztZBW2XNxVfitweUSkV rcKGiwePQQZB7uGBOa//g' US_20_1.json使用这些参数,SED在文本文件中搜索访问令牌的内容,并将其删除。这个工具使调查人员能够轻松地以自动化和高效的方式清理数据的原始文件。
由于调查项目中收集的数据是关于广告本身的,并不涉及用户的个人新闻源,所以不必处理保护个人数据的问题。
ad.watch 发布之后
1、维护,更新和调整数据库
一旦该项目被公开,定期更新数据和维护数据库也成为当务之急。这就涉及到更新频率的问题,是否每次都要从头开始收集数据,如果不收集,如何准确地从调查离开的地方收集数据。
随着 Facebook API 中数据的增加,这项调查增加了更多的国家。阿根廷和斯里兰卡在选举前不久就被添加了,新加坡的数据也被发布了。对于挪威和瑞士来说调查人员没有验证程序,但已经能够收集这些国家的数据。
Manuel:
随着发布之后的时间流逝,我还努力调整了用于收集数据的脚本,从而使收集效率更高,并且在某些任务上的人工干预最少。
2、Facebook 的回应:
发布会后不久,Facebook 的(前)广告副总裁对这个项目说了一些鼓励的话。这就很尴尬了,因为这个项目并不是为了成为一个 “可视化工具”,而是对 Facebook 缺乏系统化获取数据的能力提出了挑战。
该项目旨在强调 Facebook 的广告基础设施与社交媒体上有意义的民主参与所需条件之间的根本冲突。由于 Facebook 上的定向广告使针对性操纵的程度大幅提高,而他们未能在所有运营的国家开放这些数据,这意味着这些条件一次又一次地被破坏。

因此调查人员不希望 Facebook 选择这一项目并将其纳入寡头公司自己的透明度成功故事的一部分。

3、Twitter 审查
调查人员在发布该网站的两天后开始注意到一些奇特的事。一些其他人关于该项目的推文已经看不到了。不可能是有很多人在推特上发表了关于项目的推文后又删除了自己的推文。
很快调查人员就意识到,他们自己发布的关于该项目的推文也不见了。他们最初并没有注意到这一点,因为自己都能看到自己的推文。然而最终才意识到,他们彼此间已经看不到对方的推文了。
重要内容,关于推特审查您应该知道的事,见《推特骇客报告证实了用于社交媒体审查的工具的存在》
如上面文章所示,这就是被称为 “影子禁令” 的东西。
这种审查非常难以发现,因为这些推文的作者自己仍然可以看到推文,不会引起任何怀疑。而且这种现象已经是人们观察到的经常性现象,例如,当涉及到与克什米尔问题有关的任何推文和用户账户时。
调查人员决定立即通过向 Twitter 的支持团队报告来处理这个问题。一天后仍然没有收到他们的回复。然后调查人员发布了以下呼吁:

到此时,不仅曾经发布的关于该项目的推文无法被其他人看到,并且,再也无法发布带有该项目URL的推文。调查人员发现其他人也遇到同样的问题。

更奇怪的是,该项目的URL在推特私信中也被阻止 —— 也就是甚至无法通过私信分享。

调查人员获得了许多朋友,同事和陌生人的支持,与他们联系并建议与 Twitter 上的工作人员进行联系。
同时,调查人员发现,有人试图在 LinkedIn 上发布该项目的链接,也收到了一条警告信息。
推测认为,这个URL可能已经被标记在平台的某种集中式黑名单上了。
事实确实如此,因为调查人员发现,其中一家对该URL进行评级并建立黑名单的安全公司 —— https://fortiguard.com/webfilter —— 确实因被人举报将 ad.watch 列为了垃圾邮件。调查人员向他们提出了上诉,并收到了回复,说他们已经将其重新归类为广告(有趣 …… 一个揭露广告宣传的项目被归为了 “广告”)。

最终,Twitter 移除了这个影子禁令,但是没有提供任何解释。
调查还在继续;有人让调查人员与 Twitter 的一位工作人员取得联系,他似乎很想提供帮助,但是没有任何进展。调查人员们还探讨了使用不同渠道尝试获得有关封杀原因的解释的可能性,包括通过使用欧洲 GDPR 中的解释权。理论上,解释权可以迫使 Twitter 报告审查发生的原因,如果是算法上的原因。
关键要点
从工具中的技术故障到政策中的真诚承诺,调查人员了解到了信息经济的地下世界,即 出售个人数据用于营销、以及它对人们的社会政治现实的巨大影响。
除了 Facebook 之外,这个项目还让人们了解到那些从事提取和利用每个人的生活数据赚钱的公司的思考方式和运作方式。
这个项目就是要相信,一个两人的小团队就可以以某种方式挑战像 Facebook 这样的巨无霸实体,只因它的资源规模和叙事能力。这意味着,调查人员一直处于这样的风险之下:API访问权随时会被撤销,或者调查采取的方法被归类为违反 Facebook 的使用条款,甚至考虑到 Facebook 可以访问调查人员的许多敏感信息,这些信息可能会被用于破坏性的用途。
总体而言,影响该项目制定的因素有很多:
了解这个环境中存在的差距
相信当事情不简单时,总会有一种方法可以克服限制
伸出援手并受益于朋友的慷慨建议
认真对待数据通信
在事后看来,这些方面都有所帮助。
从2020年1月开始,这个项目正在朝着新的方向发展:调查人员正在努力让社交媒体上的政治广告信息更容易被世界不同地区的不同人群所消化;也在绕回最初的目标,即 设计一种方法,让任何希望自己查阅数据的人都可以下载。
数据库的维护和更新也令人忙碌。随着全球政治格局的变化以及新政党和联盟的出现,调查人员收到了来访者的帮助,他们通过电子邮件发送了要添加到 ad.watch 的新页面。
希望在中国有计划构建类似项目的调查人员能从这篇记录中获得经验和灵感。
该项目的更新将持续。如果您对这项调查感兴趣,请通过 ad.watch 访问,或通过 info@ad.watch 给他们写信。⚪️
ad.watch — Investigating Political Advertisements on Facebook