



人类数据库和算法劳工:Facebook 的算法工厂 (第2部) —— 关于数字极权是如何折腾你的
【2019年5月22日存档】本系列调查仅以 facebook 为例,事实上 FATBAG(Facebook Amazon Tencent Baidu Alibaba Google)都在干同样的事,只是方法略与不同、范围或大或小。您完全可以利用本系列演示的思路和提供的工具对任何一个数字极权作出独立调查。这一过程能帮助您和您的读者更深刻地理解我们所有人正在遭遇什么。

在著名的 ”Postscript on the Societies of Control” 中,Deleuze 设想了一种权力形式,它不再基于个人的生产,而是基于个体的调制。个人被解构为通过“数据库”管理的数字足迹……
继续前文。
研究工具和方法:如何存储数据、以及内部使用何种算法是最难调查的部分。幸运的是,找到了一个知识来源,让我们对这些神秘的算法过程有了一些了解:所有公开的 Facebook 专利的数据库。
我们发现 Facebook 注册了大约 8000 种不同的专利。基于它们,我们创建了对这个黑匣子内发生的事的一些可能解释。另一个主要信息来源是 Facebook Graph API,这是第三方开发人员将数据输入和移出 Facebook 平台的主要方式。

存储数据
在我们探索 Facebook 如何存储和分析数据的不同方式之前,了解社交图的概念非常重要,社交图是将所有数据连接到一个结构的元结构。
社交图的故事是通过将 Facebook 帝国内外的每条信息互连到一个单独的图中来驾驭他们对元数据世界的统治和野心。“这就是 Facebook 工作的原因”,马克·扎克伯格在 2007 年将 Facebook 的力量归功于社交图。
社交图是 Facebook 如何表示其所有数据的方法,它基本上包括两件事:对象,也称为节点;和描述这些节点之间的连接,也称为边缘。

每个用户、地点、照片、群组、活动,在 Facebook 上创建或上传的所有内容都是 Facebook 数据库中具有自己 ID 的唯一对象。例如,当您点赞 Facebook 上的某些图片时,会在两个对象之间创建连接<like>,即 <userID> 和 photo <photoID>。此照片可以包含许多其他连接,即点赞相同照片的其他用户、与该照片相关联的位置、或在该照片上标记的用户。
根据 Facebook API,Facebook 社交图中存在不同类型的节点:(在这里看大图)
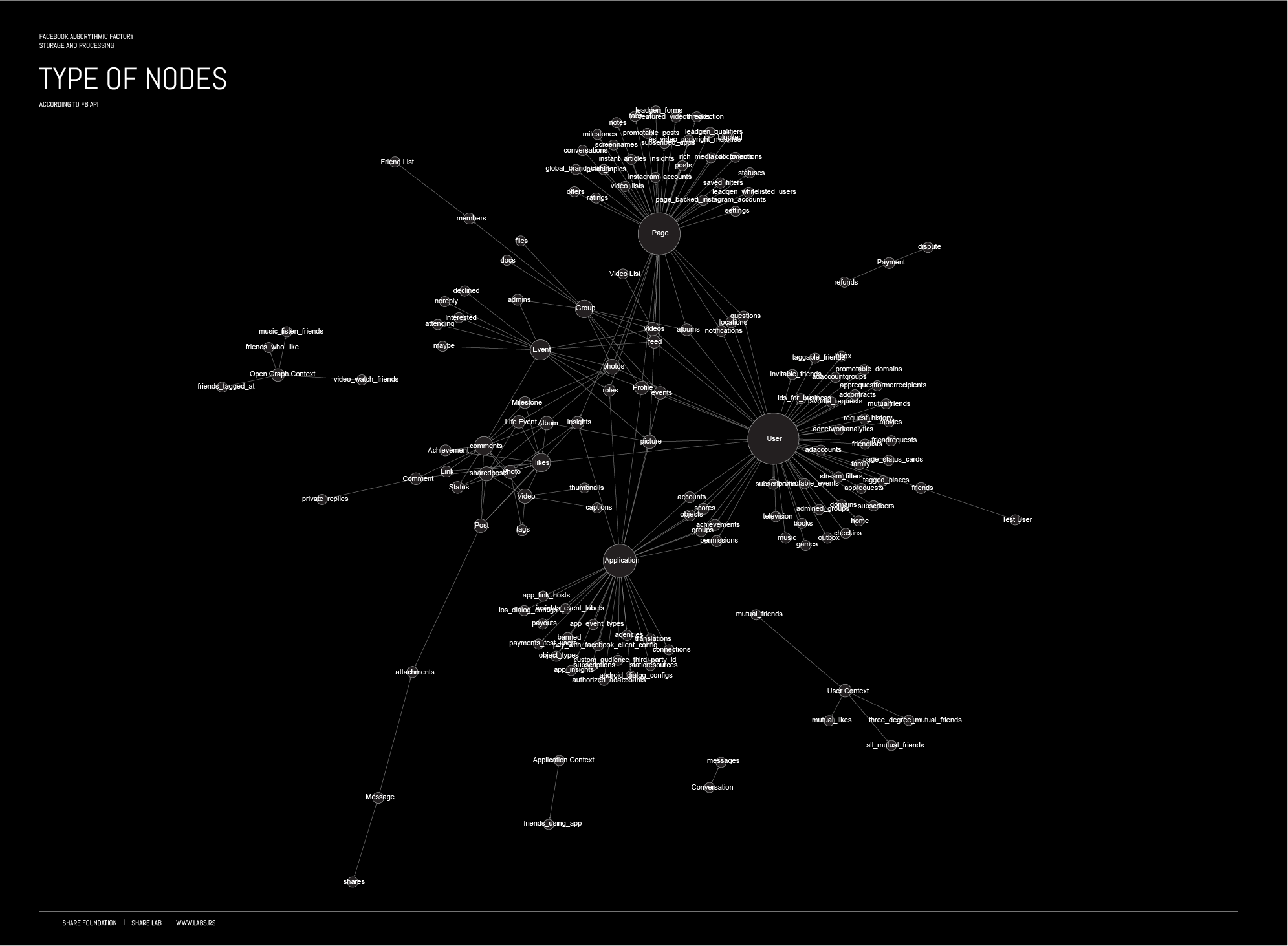{kind=link}

通过使用社交图,Facebook 能够将点赞相同照片的不同用户联系起来,或者将照片上标记的人与照片所属的位置联系起来。
⚠️ Facebook 帝国世界是由数十亿个对象组成的庞大社交图,由不同类型的链接互连。
喂养社交图
⚠️ 根据 Facebook 的几十项专利,有3个不同的商店,数据库提供社交图谱,并存储我们创建的所有数据、元数据和内容。
Action store — 维护描述用户操作的信息;
Content Store — 存储表示各种类型内容的对象;
Edge store — 存储描述用户与其他对象之间连接的信息。
Content Store 和 Edge Store 一起基本上是一个数据库,主要元结构的结构资源,社交图将所有对象和连接形成一个结构。
我们在Facebook上的所有操作都由“行动和内容记录器”记录,这些记录器为 Action and Content stores 提供新数据,不断扩展关于我们的数据库,它们由 Facebook 拥有,并很可能与许多人共享。(这里点击下面的大图)
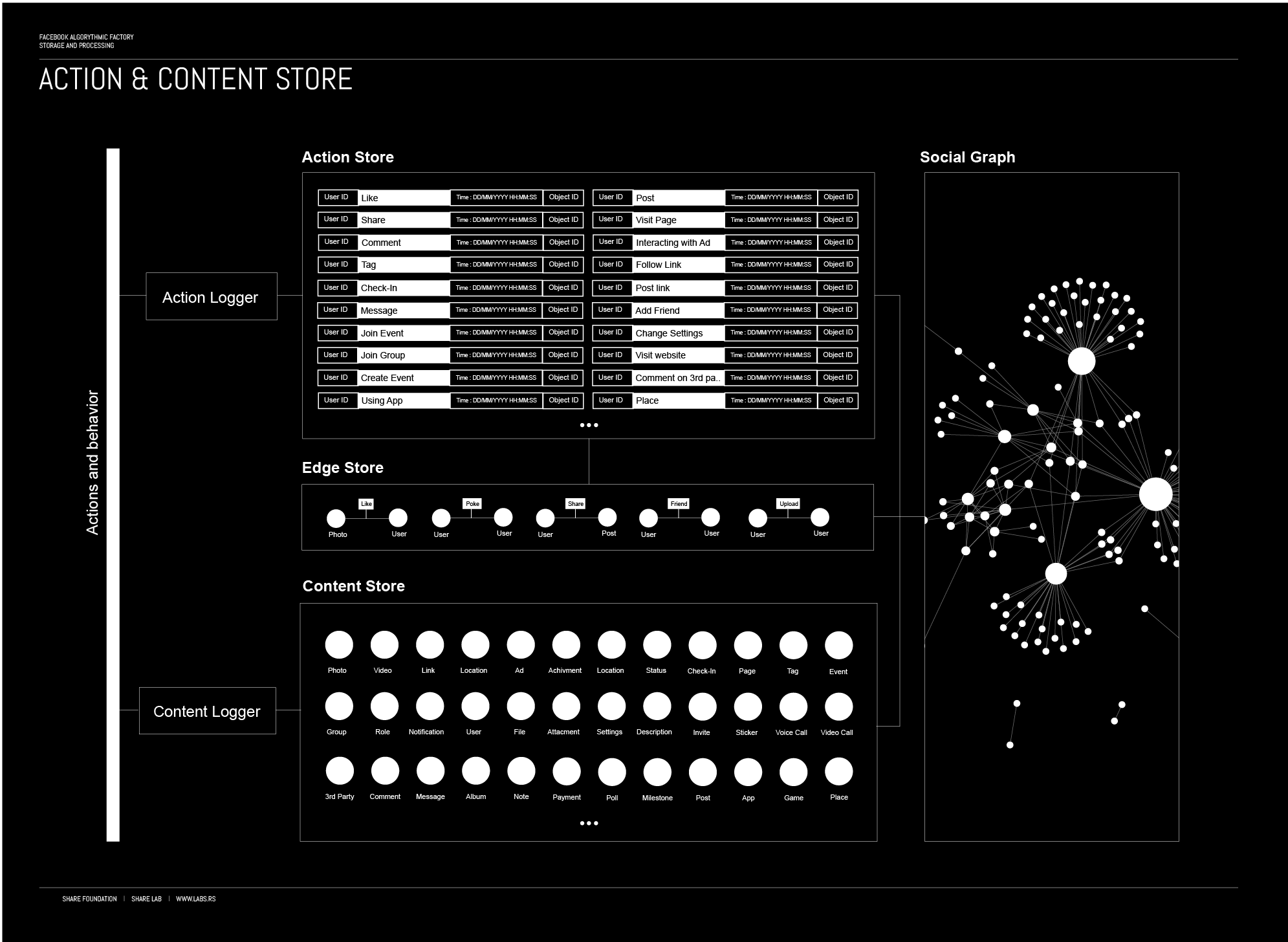{kind=link}
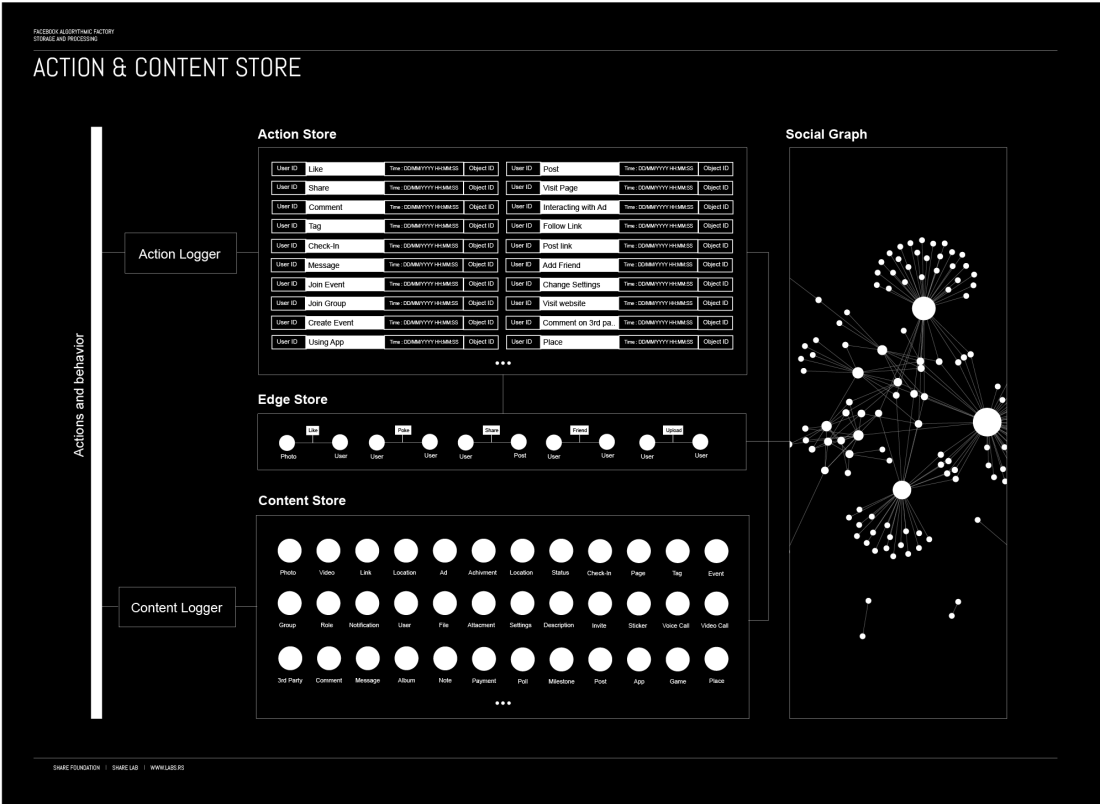
Action Store
每次点击、滚动、分享等动作,基本上你在 Facebook 上做的任何事都由行动记录器收集并存储在 Action Store 中。Action Store 维护描述用户动作的信息,以及在向 Facebook 传达信息的第三方网站上执行的动作。
操作或交互的示例包括:评论帖子、共享链接、标记对象、签到物理位置、评论相册、向另一个用户发送消息、加入活动、加入群组、粉丝品牌页面、创建事件、授权应用程序、使用应用程序、与广告交互、以及参与交易。
Content Store
这个 Content Store 存储表示各种类型内容的对象,例如页面发布、状态更新、照片、视频、链接、共享内容项目、游戏应用程序成就、本地企业的登记事件、品牌页面、或任何其他类型的内容。对象可以由用户创建,或者在某些情况下从第三方应用程序(其他网站或应用程序)接收。
Edge Store
这个 Edge Store 存储描述用户与其他对象之间连接的信息。一些边缘可以由用户定义,允许用户指定他们与其他用户的关系。当用户与对象交互时生成其他边缘,例如表达对页面的兴趣,与其他用户共享链接以及评论其他人发布的帖子等等。边缘存储还存储其他信息,例如对象的关联性分数,兴趣以及我们将在之后介绍的算法处理生成的其他信息。
Profile Store
正如我们已经提到的,我们所有人的行动数据被收集并存储在动作、内容和 Profile Store 中。另一方面,我们在个人资料信息部分中分享的有关我们自己的信息也存储在 Profile Store 中。(这里点击下面的大图)
{kind=link}
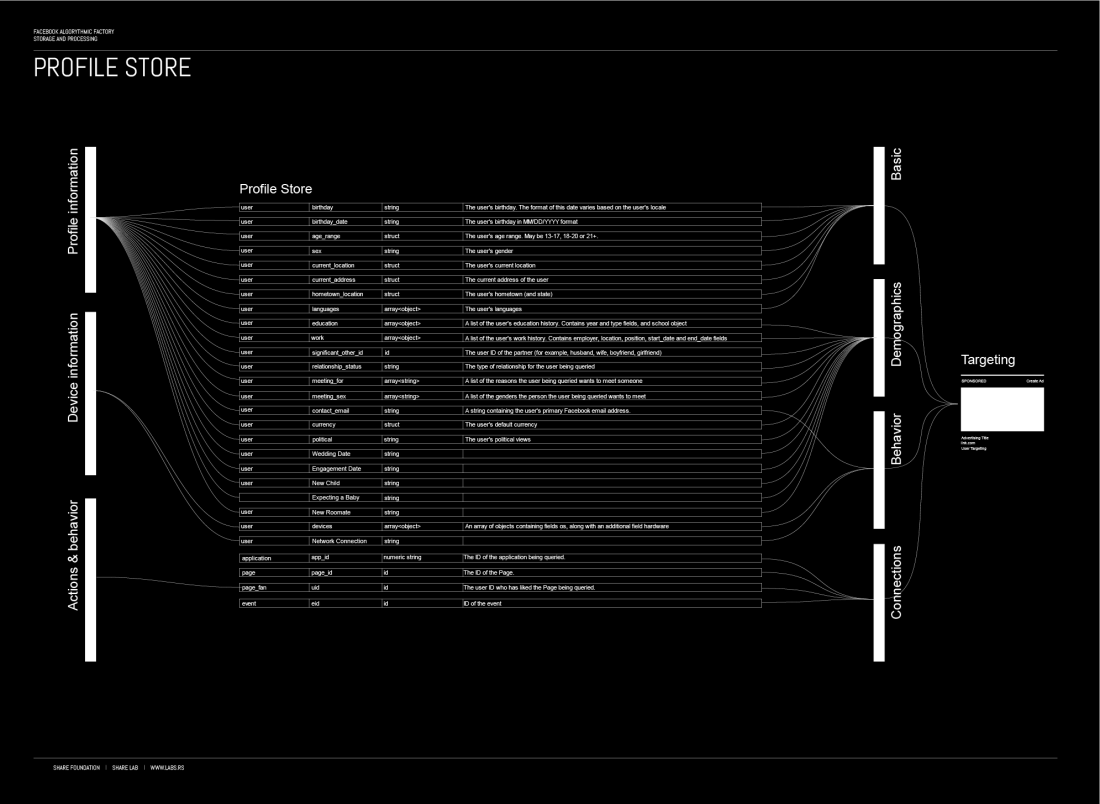
每个用户被与用户简档相关联,该用户简档存储在用户简档存储中。用户简档包括关于用户明确共享的声明性信息,并且还可以包括由 Facebook 执行的其他数据收集和分析手段推断的简档信息。
用户简档可以包括一个或多个直接特征,其唯一地标识与用户配置文件相关联的例如电子邮件地址、或电话号码。这些信息可用于识别 Facebook 之外的用户,指示用户配置文件和附加用户配置文件与同一用户相关联。
这允许 Facebook 跟踪用户并合并来自其他来源的信息。结合 Facebook 的“实名制”,它完全可以准确地将您的用户档案与您的真实身份相关联。“Facebook 是一个人们使用真实身份的社区。我们要求每个人都提供他们的真实姓名,以便您始终知道您与谁联系“…他们自己说的。
这些结构就是 Facebook Factory 的建筑物,其中资源材料,从我们所有人的行为中提取的数据,被存储并准备供算法工作者处理。在下一章中,我们将探讨一些最有趣的 Facebook 工作人员的深度权力结构 — — 将行为数据转化为最终产品的算法。
数据处理:算法劳工的剖析、任务和职责
了解算法如何处理大量数据以及它们究竟是做什么的,对于理解可能利用我们的个人数据的形式、以及每天影响数十亿人的大规模操纵机制,非常重要。
我们在这项研究中的主要目标之一是尝试对这些过程进行独立的洞察,尝试提出不同的测量方法,或从外部独立审计算法的潜在方法,但我们遇到了很多困难。尽管我们没有设法根据实际数据创建方法论,但对 Facebook 专利的研究让我们深入了解了一些最重要的流程。

行动数据分析
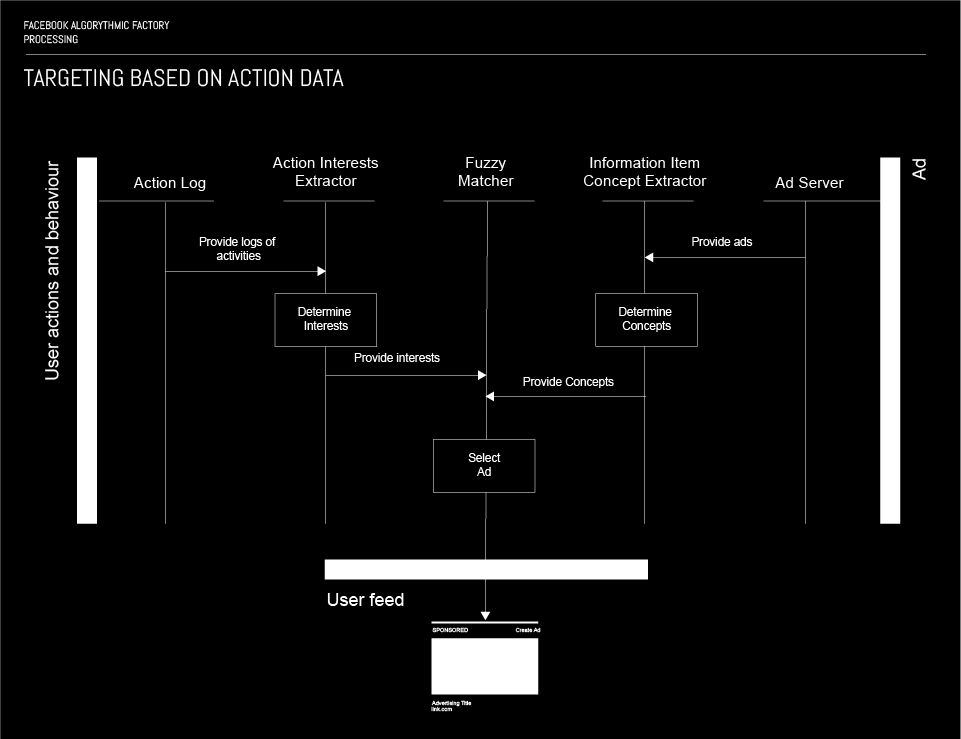
正如之前所解释的那样,Facebook 上的每一项活动都存储在所谓的 Action store 中。这意味着动作存储是一个庞大的结构化用户活动数据集,使其成为目标机制的一个非常方便的选择。(点击这里看下面大图)
{kind=link}
该过程的说明
模糊匹配算法用作基于来自 action store 的数据进行定向的主要机制。发生两个并行过程以生成模糊匹配器的输入。首先,活动日志通过 Action Interest Extractor 从 Action 日志中获取。在 Action Interest Extractor 中加载这些日志后,特定用户的兴趣列表将仅根据 Action 日志中的数据确定,即他的活动(点击、like、评论、分享等等)。然后,将感兴趣的列表作为查询转发给模糊匹配器。
第二个过程是为模糊匹配器所针对的用户选择适当的广告的过程。此过程的第一步是广告服务器向信息项概念提取器提供广告。一旦信息项概念提取器加载了一组广告,就会对它们进行分析,并确定每个广告的概念,即为每个广告分配一个表示其概念的属性。
最后,模糊匹配算法使用兴趣作为查询来执行搜索; 因此,选择与查询最匹配的广告,然后将其投放给目标用户。
内容分析
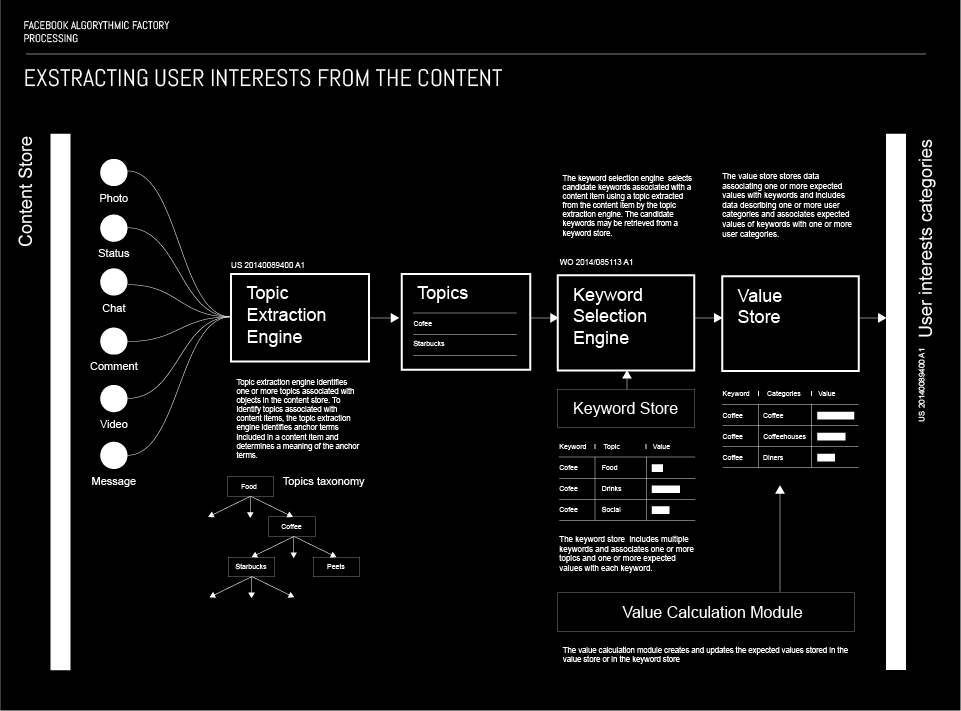
在前几段中,解释了使用 Action store 中的数据来定位用户的机制。除了该数据,来自内容存储库的数据也用于定位用户。毋庸置疑,在这种情况下,定位是基于用户以多种不同方式在 Facebook 上发布的内容。(点击这里看下面大图)
{kind=link}

基于内容的定位有两个相关方面。第一个是主题,第二个是关键字。当用户向 Facebook 发布某种内容时,有一个主题提取引擎,用于标识与该内容相关联的一个或多个主题。为了将主题与内容相关联,提取引擎对其进行分析并识别包含在内容中的锚定术语并确定其含义。
该过程的说明
使用提取的主题,算法定义关键字列表并将它们与一个或多个期望值相关联。该算法使用关于用户的信息来确定与列表上的候选关键字相关联的值。分配的值用于对候选关键字进行排名,最高排名被选择为能最精确定义内容的一个。
算法使用在用户和内容中的关键字之间创建的连接来确定下一步给你扔什么饲料。
基于内容定位的重要输入也来自 Action store,它与广告定位的负面信号相关。事实上,这是一组用户可能对此产生负面情绪的东西,并用于标记用户不希望看到的东西。当 Facebook 基于用户不喜欢特定对象(内容)的行为来确定时,它确定对象的主题并将负面情绪与他们相关联。负面情绪和主题之间的关联用于降低与所述主题匹配的内容被提供给用户的可能性。
这就是为什么如果你一直呆在集中化的网络上只会形成认知封闭,因为你再也看不到与自己不一致的观点、看不到可以帮助提升认知的信息。如果我们所有人都呆在这里,就是严重的气泡化和极化,为操纵者提供了极大便利。(点击这里看下面大图)
{kind=link}
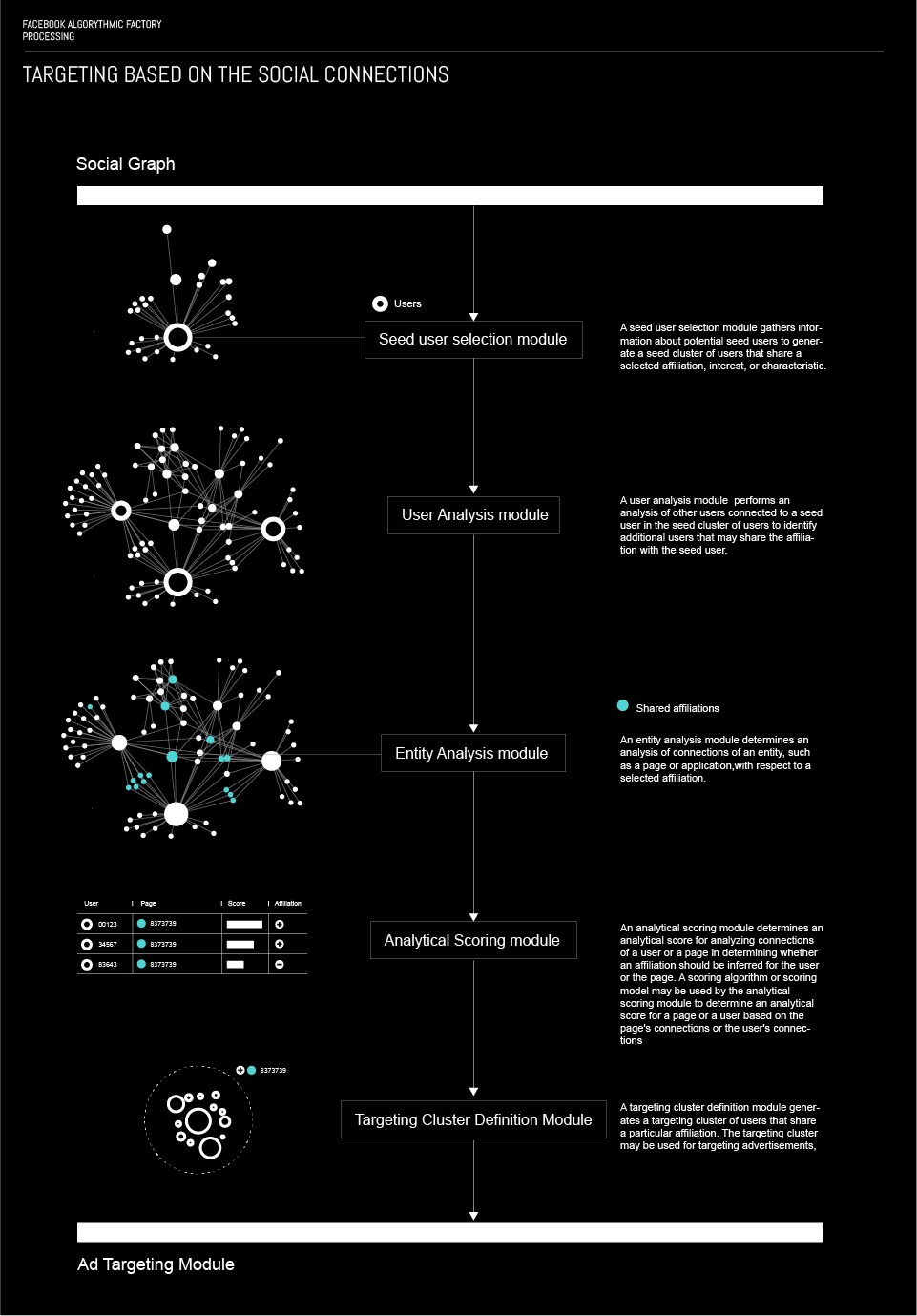
通过形成用户的逻辑结构来收集用于精确定向的重要数据。Facebook 将特定属性的用户分组到被称为种子集群的结构中。一旦创建了种子集群,就会检索与该用户相关的一组其他用户或对象。
在这些集合中,算法确定集合中的用户是否与主要用户共有相同的属性。确定过程基于次要用户的明确声明、对其连接的分析、并使用随机游走算法。结果用于确定辅助用户是否也可以与群集关联。因此,建立了定位群集,可用于定位用户并向其展示特定内容。
该过程的说明
通过测量群集中用户对特定内容的点击率或测量群集中用户的负面反馈,来测试这些群集的可信度。除此之外,用户可以根据他们与页面、应用程序等的交互进入群集。
形成群和子群的过程使用几个不同的模块。首先,种子用户选择模块,其收集关于潜在种子(主要)用户的信息,并创建共有特定从属关系、兴趣或特征的用户的种子群集。在第一阶段,算法选择在其配置文件上明确声明这些属性的用户(如页面等)。但是,与用户相关的点赞、评论、签到等活动可用于聚类。
第二个模块用于根据群成员(已在群集中的用户)创建子群,方法是探索其活动和属性,并检查它们是否可以构成群的一部分。这些次要用户的数据收集过程类似于对种子用户使用的过程。
实体分析模块用于基于用户与页面或应用程序的交互来确定用户的属性。例如,如果有人支持某个政党,该算法假设他们会对某些类型的汽车感兴趣,因为大多数使用 Facebook 应用程序显示最近卖点的用户支持所述政党。该模块的作用是根据人们与之交互的对象以及最常与这些对象进行交互的用户类型,对人进行分组。
可以通过评估用户与其他用户的连接来确定用户的某些属性。这是由分析评分模块完成的。此模块通过评估用户与其他人的连接来确定用户的特定属性。例如,如果用户与喜欢白葡萄酒的其他用户之间存在一些弱连接,并且与喜欢红葡萄酒的用户有更强的连接,则此模块将基于连接的强度(可能基于相互交互、签到、标签等)将主要用户视为喜欢红酒的用户。
一旦某些属性由前述四个模块确定,目标群集定义模块就生成共享相同属性的用户群集。群集用于投放特定类型的广告,但也用于特定的用户可能喜欢的内容定位。这样,除了产生收益之外,⚠️ Facebook 还基于偏好控制一组算法建立起了用户的信息流 — — 操纵了人们的认知。在某种程度上,这可以被视为审查制度。
使用上述模块形成群和子群作为完整流程的过程具有几个步骤。首先,用户基于类似的属性构建为子群; 然后识别该群的中心用户,并通过它们识别整个群的特征。然后,子群中的所有用户通过其属性的相似性对中央用户的相似性进行排序。最后,该子群被标记为一个完整的紧凑单元; 例如,喜欢红酒和哈利波特的人。
根据事件定位用户
该算法基于若干不同标准执行事件定向。可以指示用户与事件的关联的第一个也是最简单的标准就是在 Facebook 上创建的事件的 RSVP 选项。然而,由于用户可以回复 Yes,但没有参加活动,因此算法可以基于他们先前的出勤得分、他们的朋友出席人数、和一般事件历史、来计算他们是否真的会参加活动 — — 这就是行为预测。
此外,该算法也使用其他输入,例如在活动场所登记、上传活动门票的照片、在外部网站上购买门票的记录、或在帖子中标记事件等等。事件定位用于从小型私人事件到全局事件的所有等级的事件 — — 您现在能控制住自己想晒的欲望了吗?
更多:专利 WO2013074367(A2)

根据在线系统中的搜索结果定位用户
该算法利用查询用户输入到 Facebook 的搜索框中的东西。此算法的目的是为用户提供与其搜索查询相对应的内容。当使用在搜索框中输入查询时,编译匹配查询的结果,而算法尝试识别查询和结果中的结构化节点。
然后,它检索与识别的结构化节点对应的内容,同时检索有关用户的信息。在将广告与用户的信息(即属性)匹配之后,它确定应该与查询的结果一起显示哪些广告。这实际上是在用户输入查询时发生的,因此很难将其视为结构良好的东西。
更多:专利 WO 2014099558 A2
常规估测
该算法通过以小时间隔分析用户在一段时间内的地理位置,来确定用户的例程。
该算法使用由移动设备提供的关于用户地理定位的数据,例如智能手机、平板电脑或笔记本电脑,或者安装在这些设备中的传感器,即 GPS 传感器、陀螺仪或指南针; 设备上安装的Facebook 应用程序收集必要的数据并将其提供给算法。
接下来,算法分析重复、或者在一周中的某一天的某个小时处于相同位置的用户。然后算法聚集这些地理位置; 之后,群集由与群集中的地理定位质心对应的位置标记。以这种方式,算法可以确定用户居住的地方,他们工作的地方,最爱去的地方等 — — 也就是你的行踪。
更多:专利:WO 2014123982 A3

推断用户的家庭收入
该算法将用户映射到特定的收入范围。这是通过分析用户提供的信息,即 当前和过去的工作岗位、他们参加的当前和过去的教育机构、生活事件、家庭关系、和婚姻状况等,来完成的。
然而,由于用户能够向 Facebook 提供虚假信息,因此该算法进一步分析用户的行为,他们访问的网站、他们在线进行的购买等。该算法使用不同的技术将用户映射到特定范围中,包括图像分析以识别用户在上传的照片上使用的品牌、他们在帖子和搜索中使用品牌名称的频率等等。然后,这些信息用于使广告客户更容易按收入定位适当的目标群体。
更多:专利 US 8583471 B1

比较用户的财务交易
该算法所做的是通过共享类似的属性(例如年龄、位置、教育水平、工作位置等)来比较用户的购买习惯与该用户可以关联的一组用户的比较。算法分析搜索查询,访问 Facebook 和第三方网站上的外部网站和其他类型的交易。
使用此数据,该算法可以为用户提供以前的交易分析,但也可以预测未来的支出,例如,它可以通过将他以前的交易与具有相似兴趣的其他用户进行比较,来预测用户在旅行上花费的金额,比如 年龄相同、与主要用户居住在同一个城市的同群用户。
更多:专利 US 20140222636 A1
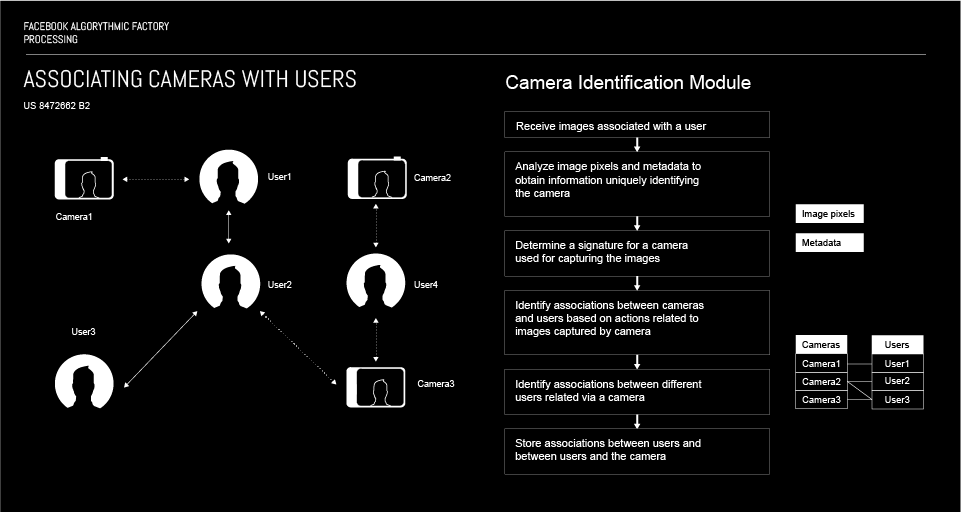
将相机与社交网络系统的用户相关联
该算法基于使用相同相机(即设备)拍摄的图片和/或视频来关联 Facebook 用户。当在 Facebook 上上传照片或视频时,用户界面、相机签名因算法而变红,并且用作上传使用相同设备(即相机)拍摄的照片或视频的用户的连接点。这可以用于检测虚假账户,具有多个账户的用户; 但也是为了社交图的目的,即推荐朋友、缩小你的视野、操纵你的认知。
更多:专利 US 8472662 B2
以上这些特色算法只是数百种不同算法中的几个例子,它们试图理解我们所有人的每一个动作和帖子,将我们分类为纳米子类别、并预测我们未来的行为。我们鼓励本文的读者自己探索可用的专利,并继续这项研究,以了解这一现象。
因为,这非常重要,关于我们如何才能摆脱这个魔掌的问题。它几乎铺天盖地了。
希望这些演示能给中国的积极人士一些提示,稍微用点心,揭露并不难。好运。⚪️